a review of Wendy Hui Kyun Chun, Discriminating Data Correlation, Neighborhoods, and the New Politics of Recognition (MIT Press, 2021)
I remember snickering when Chris Anderson announced “The End of Theory” in 2008. Writing in Wired magazine, Anderson claimed that the structure of knowledge had inverted. It wasn’t that models and principles revealed the facts of the world, but the reverse, that the data of the world spoke their truth unassisted. Given that data were already correlated, Anderson argued, what mattered was to extract existing structures of meaning, not to pursue some deeper cause. Anderson’s simple conclusion was that “correlation supersedes causation…correlation is enough.”
This hypothesis — that correlation is enough — is the thorny little nexus at the heart of Wendy Chun’s new book, Discriminating Data. Chun’s topic is data analytics, a hard target that she tackles with technical sophistication and rhetorical flair. Focusing on data-driven tech like social media, search, consumer tracking, AI, and many other things, her task is to exhume the prehistory of correlation, and to show that the new epistemology of correlation is not liberating at all, but instead a kind of curse recalling the worst ghosts of the modern age. As Chun concludes, even amid the precarious fluidity of hyper-capitalism, power operates through likeness, similarity, and correlated identity.
While interleaved with a number of divergent polemics throughout, the book focuses on four main themes: correlation, discrimination, authentication, and recognition. Chun deals with these four as general problems in society and culture, but also interestingly as specific scientific techniques. For instance correlation has a particular mathematical meaning, as well as a philosophical one. Discrimination is a social pathology but it’s also integral to discrete rationality. I appreciated Chun’s attention to details large and small; she’s writing about big ideas — essence, identity, love and hate, what does it mean to live together? — but she’s also engaging directly with statistics, probability, clustering algorithms, and all the minutia of data science.
In crude terms, Chun rejects the — how best to call it — the “anarcho-materialist” turn in theory, typified by someone like Gilles Deleuze, where disciplinary power gave way to distributed rhizomes, schizophrenic subjects, and irrepressible lines of flight. Chun’s theory of power isn’t so much about tessellated tapestries of desiring machines as it is the more strictly structuralist concerns of norm and discipline, sovereign and subject, dominant and subdominant. Big tech is the mechanism through which power operates today, Chun argues. And today’s power is racist, misogynist, repressive, and exclusionary. Power doesn’t incite desire so much as stifle and discipline it. In other words George Orwell’s old grey-state villain, Big Brother, never vanished. He just migrated into a new villain, Big Bro, embodied by tech billionaires like Mark Zuckerberg or Larry Page.
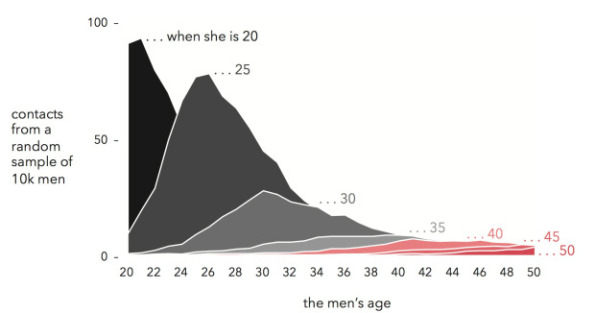
But what are the origins of this new kind of data-driven power? The reader learns that correlation and homophily, or “the notion that birds of a feather naturally flock together” (23), not only subtend contemporary social media platforms like Facebook, but were in fact originally developed by eugenicists like Francis Galton and Karl Pearson. “British eugenicists developed correlation and linear regression” (59), Chun notes dryly, before reminding us that these two techniques are at the core of today’s data science. “When correlation works, it does so by making the present and future coincide with a highly curated past” (52). Or as she puts it insightfully elsewhere, data science doesn’t so much anticipate the future, but predict the past.
If correlation (pairing two or more pieces of data) is the first step of this new epistemological regime, it is quickly followed by some additional steps. After correlation comes discrimination, where correlated data are separated from other data (and indeed internally separated from themselves). This entails the introduction of a norm. Discriminated data are not simply data that have been paired, but measurements plotted along an axis of comparison. One data point may fall within a normal distribution, while another strays outside the norm within a zone of anomaly. Here Chun focuses on “homophily” (love of the same), writing that homophily “introduces normativity within a supposedly nonnormative system” (96).
The third and fourth moments in Chun’s structural condition, tagged as “authenticity” and “recognition,” complete the narrative. Once groups are defined via discrimination, they are authenticated as a positive group identity, then ultimately recognized, or we could say self-recognized, by reversing the outward-facing discriminatory force into an inward-facing act of identification. It’s a complex libidinal economy that Chun patiently elaborates over four long chapters, linking these structural moments to specific technologies and techniques such as Bayes’ theorem, clustering algorithms, and facial recognition technology.
A number of potential paths emerge in the wake of Chun’s work on correlation, which we will briefly mention in passing. One path would be toward Shane Denson’s recent volume, Discorrelated Images, on the loss of correlated experience in media aesthetics. Another would be to collide Chun’s critique of correlation in data science with Quentin Meillassoux’s critique of correlation in philosophy, notwithstanding the significant differences between their two projects.
Correlation, discrimination, authentication, and recognition are the manifest contents of the book as it unfolds page by page. At the same time Chun puts forward a few meta arguments that span the text as a whole. The first is about difference and the second is about history. In both, Chun reveals herself as a metaphysician and moralist of the highest order.
First Chun picks up a refrain familiar to feminism and anti-racist theory, that of erasure, forgetting, and ignorance. Marginalized people are erased from the archive; women are silenced; a subject’s embodiment is ignored. Chun offers an appealing catch phrase for this operation, “hopeful ignorance.” Many people in power hope that by ignoring difference they can overcome it. Or as Chun puts it, they “assume that the best way to fight abuse and oppression is by ignoring difference and discrimination” (2). Indeed this posture has been central to political liberalism for a long time, in for instance John Rawls’ derivation of justice via a “veil of ignorance.” For Chun the attempt to find an unmarked category of subjectivity — through that frequently contested pronoun “we” — will perforce erase and exclude those structurally denied access to the universal. “[John Perry] Barlow’s ‘we’ erased so many people,” Chun noted in dismay. “McLuhan’s ‘we’ excludes most of humanity” (9, 15). This is the primary crime for Chun, forgetting or ignoring the racialized and gendered body. (In her last book, Updating to Remain the Same, Chun reprinted a parody of a well-known New Yorker cartoon bearing the caption “On the Internet, nobody knows you’re a dog.” The posture of ignorance, of “nobody knowing,” was thoroughly critiqued by Chun in that book, even as it continues to be defended by liberals).
Yet if the first crime against difference is to forget the mark, the second crime is to enforce it, to mince and chop people into segregated groups. After all, data is designed to discriminate, as Chun takes the better part of her book to elaborate. These are engines of difference and it’s no coincidence that Charles Babbage called his early calculating machine a “Difference Engine.” Data is designed to segregate, to cluster, to group, to split and mark people into micro identities. We might label this “bad” difference. Bad difference is when the naturally occurring multiplicity of the world is canalized into clans and cliques, leveraged for the machinations of power rather than the real experience of people.
To complete the triad, Chun has proposed a kind of “good” difference. For Chun authentic life is rooted in difference, often found through marginalized experience. Her muse is “a world that resonates with and in difference” (3). She writes about “the needs and concerns of black women” (49). She attends to “those whom the archive seeks to forget” (237). Good difference is intersectional. Good difference attends to identity politics and the complexities of collective experience.
Bad, bad, good — this is a triad, but not a dialectical one. Begin with 1) the bad tech posture of ignoring difference; followed by 2) the worse tech posture of specifying difference in granular detail; contrasted with 3) a good life that “resonates with and in difference.” I say “not dialectical” because the triad documents difference changing position rather than the position of difference changing (to paraphrase Catherine Malabou from her book on Changing Difference). Is bad difference resolved by good difference? How to tell the difference? For this reason I suggest we consider Discriminating Data as a moral tale — although I suspect Chun would balk at that adjective — because everything hinges on a difference between the good and the bad.
Chun’s argument about good and bad difference is related to an argument about history, revealed through what she terms the “Transgressive Hypothesis.” I was captivated by this section of the book. It connects to a number of debates happening today in both theory and culture at large. Her argument about history has two distinct waves, and, following the contradictory convolutions of history, the second wave reverses and inverts the first.
Loosely inspired by Michel Foucault’s Repressive Hypothesis, Chun’s Transgressive Hypothesis initially describes a shift in society and culture roughly coinciding with the Baby Boom generation in the late Twentieth Century. Let’s call it the 1968 mindset. Reacting to the oppressions of patriarchy, the grey-state threats of centralized bureaucracy, and the totalitarian menace of “Nazi eugenics and Stalinism,” liberation was found through “‘authentic transgression’” via “individualism and rebellion” (76). This was the time of the alternative, of the outsider, of the nonconformist, of the anti-authoritarian, the time of “thinking different.” Here being “alt” meant being left, albeit a new kind of left.
Chun summons a familiar reference to make her point: the Apple Macintosh advertisement from 1984 directed by Ridley Scott, in which a scary Big Brother is dethroned by a colorful lady jogger brandishing a sledge hammer. “Resist, resist, resist,” was how Chun put the mantra. “To transgress…was to be free” (76). Join the resistance, unplug, blow your mind on red pills. Indeed the existential choice from The Matrix — blue pill for a life of slavery mollified by ignorance, red pill for enlightenment and militancy tempered by mortal danger — acts as a refrain throughout Chun’s book. In sum the Transgressive Hypothesis “equated democracy with nonnormative structures and behaviors” (76). To live a good life was to transgress.
But this all changed in 1984, or thereabouts. Chun describes a “reverse hegemony” — a lovely phrase that she uses only twice — where “complaints against the ‘mainstream’ have become ‘mainstreamed’” (242). Power operates through reverse hegemony, she claims, “The point is never to be a ‘normie’ even as you form a norm” (34). These are the consequences of the rise of neoliberalism, fake corporate multiculturalism, Ronald Reagan and Margaret Thatcher but even more so Bill Clinton and Tony Blaire. Think postfordism and postmodernism. Think long tails and the multiplicity of the digital economy. Think woke-washing at CIA and Spike Lee shilling cryptocurrency. Think Hypernormalization, New Spirit of Capitalism, Theory of the Young Girl, To Live and Think Like Pigs. Complaints against the mainstream have become mainstreamed. And if power today has shifted “left,” then — Reverse Hegemony Brain go brrr — resistance to power shifts “right.” A generation ago the Q Shaman would have been a leftwing nut nattering about the Kennedy assassination. But today he’s a right wing nut (alas still nattering about the Kennedy assassination).
“Red pill toxicity” (29) is how Chun characterizes the responses to this new topsy-turvy world of reverse hegemony. (To be sure, she’s only the latest critic weighing in on the history of the present; other well-known accounts include Angela Nagle’s 2017 book Kill All Normies, and Mark Fisher’s notorious 2013 essay “Exiting the Vampire Castle.”) And if libs, hippies, and anarchists had become the new dominant, the election of Donald Trump showed that “populism, paranoia, polarization” (77) could also reemerge as a kind of throwback to the worst political ideologies of the Twentieth Century. With Trump the revolutions of history — ironically, unstoppably — return to where they began, in “the totalitarian world view” (77).
In other words these self-styled rebels never actually disrupted anything, according to Chun. At best they used disruption as a kind of ideological distraction for the same kinds of disciplinary management structures that have existed since time immemorial. And if Foucault showed that nineteenth-century repression also entailed an incitement to discourse, Chun describes how twentieth-century transgression also entailed a novel form of management. Before it was “you thought you were repressed but in fact you’re endlessly sublating and expressing.” Now it’s “you thought you were a rebel but disruption is a standard tactic of the Professional Managerial Class.” Or as Jacques Lacan said in response to some young agitators in his seminar, vous voulez un maître, vous l’aurez. Slavoj Žižek’s rendering, slightly embellished, best captures the gist: “As hysterics, you demand a new master. You will get it!”
I doubt Chun would embrace the word “hysteric,” a term indelibly marked by misogyny, but I wish she would, since hysteria is crucial to her Transgressive Hypothesis. In psychoanalysis, the hysteric is the one who refuses authority, endlessly and irrationally. And bless them for that; we need more hysterics in these dark times. Yet the lesson from Lacan and Žižek is not so much that the hysteric will conjure up a new master out of thin air. In a certain sense, the lesson is the reverse, that the Big Other doesn’t exist, that Big Brother himself is a kind of hysteric, that power is the very power that refuses power.
This position makes sense, but not completely. As a recovering Deleuzian, I am indelibly marked by a kind of antinomian political theory that defines power as already heterogenous, unlawful, multiple, anarchic, and material. However I am also persuaded by Chun’s more classical posture, where power is a question of sovereign fiat, homogeneity, the central and the singular, the violence of the arche, which works through enclosure, normalization, and discipline. Faced with this type of power, Chun’s conclusion is, if I can compress a hefty book into a single writ, that difference will save us from normalization. In other words, while Chun is critical of the Transgressive Hypothesis, she ends up favoring the Big-Brother theory of power, where authentic alternatives escape repressive norms.
I’ll admit it’s a seductive story. Who doesn’t want to believe in outsiders and heroes winning against oppressive villains? And the story is especially appropriate for the themes of Discriminating Data: data science of course entails norms and deviations; but also, in a less obvious way, data science inherits the old anxieties of skeptical empiricism, where the desire to make a general claim is always undercut by an inability to ground generality.
Yet I suspect her political posture relies a bit too heavily on the first half of the Transgressive Hypothesis, the 1984 narrative of difference contra norm, even as she acknowledges the second half of the narrative where difference became a revanchist weapon for big tech (to say nothing of difference as a bonafide management style). This leads to some interesting inconsistencies. For instance Chun notes that Apple’s 1984 hammer thrower is a white woman disrupting an audience of white men. But she doesn’t say much else about her being a woman, or about the rainbow flag that ends the commercial. The Transgressive Hypothesis might be the quintessential tech bro narrative but it’s also the narrative of feminism, queerness, and the new left more generally. Chun avoids claiming that feminism failed; but she’s also savvy enough to avoid saying that it succeeded. And if Sadie Plant once wrote that “cybernetics is feminization,” for Chun it’s not so clear. According to Chun the cybernetic age of computers, data, and ubiquitous networks still orients around structures of normalization: masculine, white, straight, affluent and able-bodied. Resistant to such regimes of normativity, Chun must nevertheless invent a way to resist those who were resisting normativity.
Regardless, for Chun the conclusion is clear: these hysterics got their new master. If not immediately they got it eventually, via the advent of Web 2.0 and the new kind of data-centric capitalism invented in the early 2000s. Correlation isn’t enough — and that’s the reason why. Correlation means the forming of a general relation, if only the most minimal generality of two paired data points. And, worse, correlation’s generality will always derive from past power and organization rather than from a reimagining of the present. Hence correlation for Chun is a type of structural pessimism, in that it will necessarily erase and exclude those denied access to the general relation.
Characterized by a narrative poignancy and an attention to the ideological conditions of everyday life, Chun highlights alternative relations that could hopefully replace the pessimism of correlation. Such alternatives might take the form of a “potential history” or a “critical fabulation,” phrases borrowed from Ariella Azoulay and Saidiya Hartman, respectively. For Azoulay potential history means to “‘give an account of diverse worlds that persist’”; for Hartman, critical fabulation means “to see beyond numbers and sources” (79). A slim offering covering a few pages, nevertheless these references to Azoulay and Hartman indicate an appealing alternative for Chun, and she ends her book where it began, with an eloquent call to acknowledge “a world that resonates with and in difference.”
_____
Alexander R. Galloway is a writer and computer programmer working on issues in philosophy, technology, and theories of mediation. Professor of Media, Culture, and Communication at New York University, he is author of several books and dozens of articles on digital media and critical theory, including Protocol: How Control Exists after Decentralization (MIT, 2006), Gaming: Essays in Algorithmic Culture (University of Minnesota, 2006); The Interface Effect (Polity, 2012), Laruelle: Against the Digital (University of Minnesota, 2014), and most recently, Uncomputable: Play and Politics in the Long Digital Age (Verso, 2021).